

اخبار ، مقالات و تحقیقات گروهی را دنبال کنید.
آموزش 4 تکنیک جدید و جامع در گوگل ارث انجین

















در این محصول جامع آموزشی که از جدیدترین محصولات حوزه سنجش از دور و مطالعات کشاورزی می باشد به موضوعات جدید و پرکاربرد پرداخته شده است. مباحث مختلف این محصول جامع آموزشی در 4 بخش مجزا ارائه شده است: 1.نرمال سازی تصویر (Image Normalization) با دو روش مختلف (روش Z-score و روش استفاده از مقادیر min و max) 2.محاسبه معیارهای…
در این محصول جامع آموزشی که از جدیدترین محصولات حوزه سنجش از دور و مطالعات کشاورزی می باشد به موضوعات جدید و پرکاربرد پرداخته شده است.
مباحث مختلف این محصول جامع آموزشی در 4 بخش مجزا ارائه شده است:
1.نرمال سازی تصویر (Image Normalization) با دو روش مختلف (روش Z-score و روش استفاده از مقادیر min و max)
2.محاسبه معیارهای کمی تفکیک پذیری کلاس های کاربری مانند فاصله ماهالانوبیس، فاصله باتاچاریا و فاصله جفریس-ماتوسیتا
3.شناسایی GCPs هایی که در فرآیند طبقه بندی به اشتباه طبقه بندی شدند (Identify Misclassified GCPs).
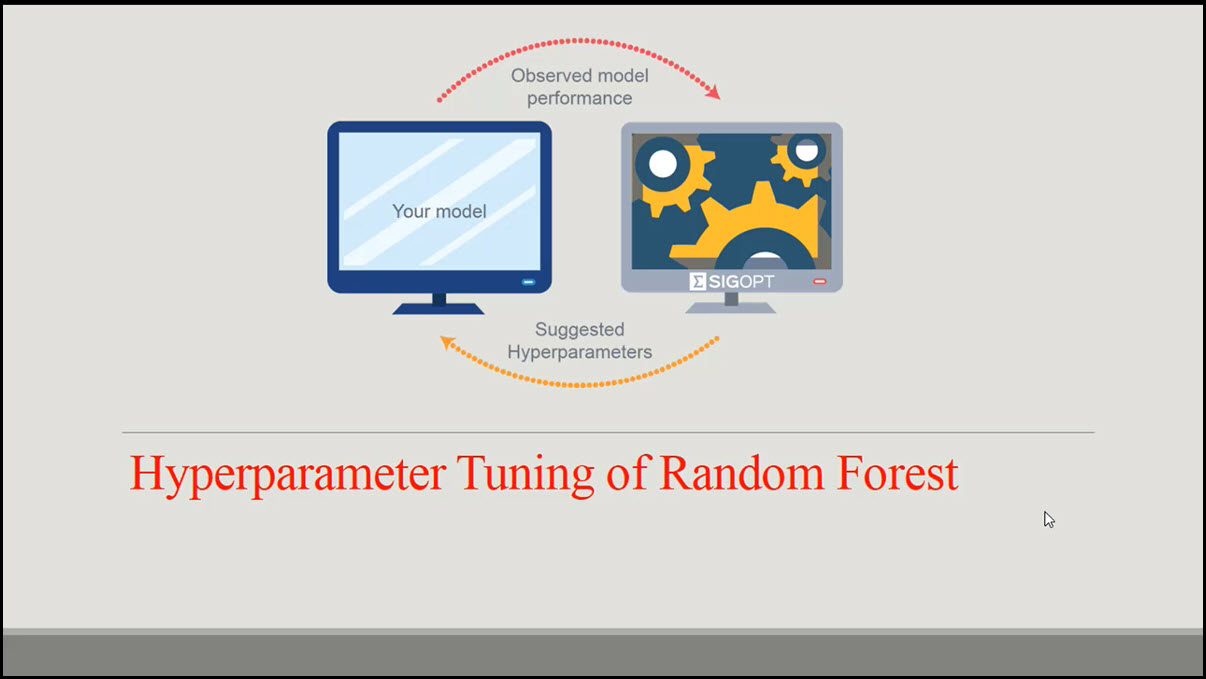
4.تنظیم فرا پارامتر های الگوریتم جنگل تصادفی (Hyperparameter Tuning).
پلتفرم مورد استفاده در جهت پیشبرد مباحث این محصول جامع آموزش گوگل ارث انجین می باشد. از جمله دلایل انتخاب سامانه گوگل ارث انجین به منظور انجام بخش های مختلف این محصول جامع آموزشی می توان به توان محاسباتی بالای آن، امکان فراخوانی تصاویر ماهوارهای مختلف، عدم محدودیت آن به سخت افزار، سرعت پردازشی بالا و راحتی کار با سامانه حتی برای افرادی که آشنایی محدودی با زبان برنامه نویسی جاوااسکریپت دارند، اشاره کرد.
مشخصات محصول
- مدرس: مهدی نادری
- تخصص: کارشناس سنجش از دور و پردازش تصاویر ماهواره ای
- موضوع: محصول جامع آموزشی حاوی 4 بخش نرمالسازی تصویر، محاسبه معیار های کمی تفکیک پذیری کلاس های کاربری، شناسایی GCPs های به اشتباه طبقه بندی شده و تنظیم فرا پارامتر های الگوریتم جنگل تصادفی
- مدت زمان آموزش: 4 ساعت و 28 دقیقه ⏰
- نرم افزار: سامانه گوگل ارث انجین 🌏
- مخاطب: علاقهمندان به سنجش از دور، مطالعات کابری اراضی، مطالعات کشاورزی و …
- نوع آموزش: ویدئویی 📺
- پیش نیاز: آشنایی مقدماتی با سامانه گوگل ارث انجین
ویدئوی معرفی
تهیه آموزش
جهت تهیه این اموزش بر روی دکمه زیر 👇 کلیک کنید و پس از پرداخت وجه بلافاصله ویدئوهای آموزشی را دانلود نمایید:
عناوین آموزشی
عناوین آموزشی این محصول عبارت اند از:
👈 بخش اول : نرمال سازی تصویر:
- تببین مباحث تئوری نرمال سازی تصویر ماهواره ای
- معرفی منطقه مورد مطالعه به سامانه ارث انجین
- فراخوانی تصاویر ماهواره ای سنتینل-2 و اعمال فیلترهای مکانی، زمانی و درصد ابر
- ماسک ابر، برف و سایه ابر از تصاویر سنتینل-2
- محاسبه شاخص های مختلف طیفی مانند شاخص بهبود یافته پوشش گیاهی (EVI) و …
- استفاده از سایر لایه های اطلاعاتی مانند مدل رقومی سطح (DSM) سنجنده ALOS و محاسبه مقدار شیب
- نرمال سازی تصویر با روش استفاده از مقادیر مینیمم و ماکسیمم (روش اول)
- نرمال سازی تصویر با استفاده از نمره آماری z یا Z-Score (روش دوم)
- مقایسه تصویر اصلی با تصویر نرمال شده به روش اول از طریق محاسبه همزمان مقادیر مینیمم و ماکسیمم
- مقایسه تصویر اصلی با تصویر نرمال شده به روش دوم از طریق محاسبه همزمان مقادیر میانگین و انحراف معیار
👈 بخش دوم : محاسبه معیارهای کمی تفکیک پذیری کلاس های کاربری :
- تبیین مباحث تئوری تفکیک پذیری کلاس های کاربری
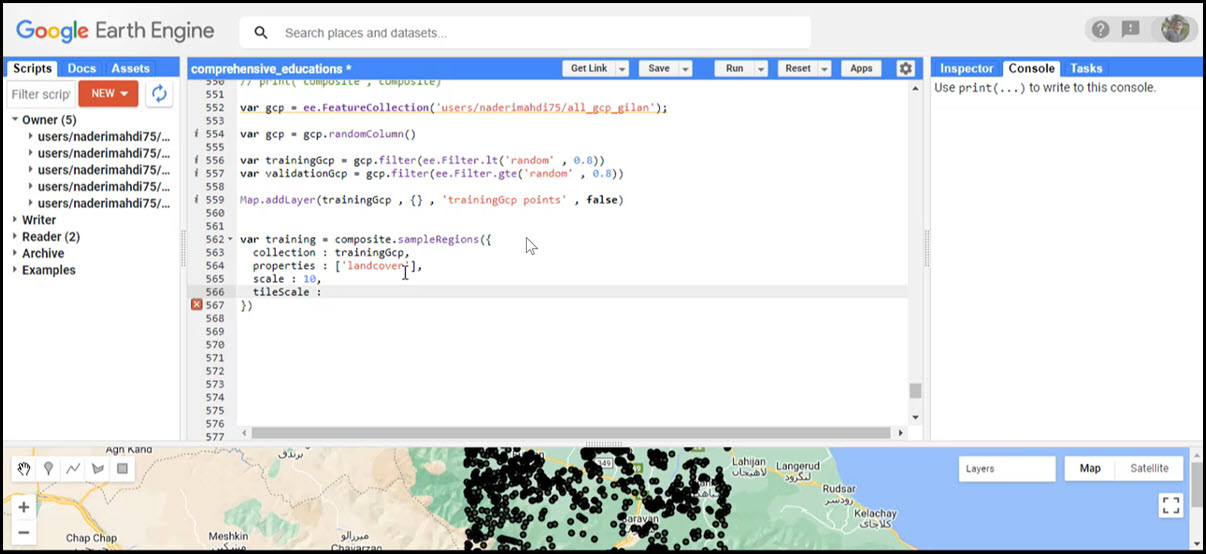
- معرفی داده های زمینی یا GCPs به سامانه ارث انجین
- مرتبط ساختن تصویر نرمال شده حاصل از بخش 1 با داده های زمینی (GCPs)
- تبدیل باند های تصویر به وکتور یا بردار
- محاسبه مقادیر میانگین و کوواریانس مجموعه دادهها
- محاسبه معیار یا فاصله ماهالانوبیس
- محاسبه معیار یا فاصله باتاچاریا
- محاسبه معیار یا فاصله جفریس-ماتوسیتا
👈 بخش سوم : شناسایی GCP های به اشتباه طبقه بندی شده (Identify Misclassified GCPs) :
- تبیین مباحث تئوری شناسایی GCP های به اشتباه طبقه بندی شده
- استفاده از تصویر نرمال شده مستخرج از بخش اول
- مرتبط ساختن تصویر نرمال شده با داده های زمینی (GCPs)
- آموزش طبقه بند کننده جنگل تصادفی با تنظیم فرا پارامتر های آن
- ایجاد نقشه طبقه بندی
- اعتبارسنجی نقشه طبقه بندی با استفاده از معیار های صحت کلی، ضریب کاپا و …
- محاسبه داده های زمینی (GCPs) مرتبط با کلاس کاربری جنگل به اشتباه طبقه بندی شده
- محاسبه داده های زمینی (GCPs) مرتبط با کلاس کاربری پوشش گیاهی به اشتباه طبقه بندی شده
- محاسبه تمامی داده های زمینی (GCPs) به اشتباه طبقه بندی شده مرتبط با کلاس های کاربری
- نمایش تمامی داده های زمینی (GCPs) به اشتباه طبقه بندی شده بر روی map سامانه ارث انجین و بررسی آنها
👈 بخش چهارم : تنظیم فراپارامترهای الگوریتم جنگل تصادفی (Hyperparameter Tuning of Random Forest):
- تبیین مباحث تئوری تنظیم فراپارامتر های الگوریتم جنگل تصادفی
- معرفی منطقه مورد مطالعه به سامانه ارث انجین
- فراخوانی تصاویر ماهواره ای سنتینل-2 و اعمال فیلترهای مکانی، زمانی و درصد ابر
- ماسک ابر، برف و سایه ابر از تصاویر سنتینل-2
- محاسبه شاخص های مختلف طیفی مانند شاخص خاک خشک (BSI) و …
- استفاده از سایر لایه های اطلاعاتی مانند مدل رقومی سطح (DSM) سنجنده ALOS و محاسبه مقدار شیب
- نرمالسازی تصویر با روش استفاده از مقادیر مینیمم و ماکسیمم ((X – Xmin) / (Xmax – Xmin) )
- معرفی داده های زمینی (GCPs) به سامانه ارث انجین و تبدیل آنها به داده های آموزشی و تست
- مرتبط ساختن داده های آموزشی با تصویر ماهواره ای نرمال شده
- آموزش طبقه بند جنگل تصادفی با استفاده از داده های آموزشی و تنظیم فراپارامتر های آن
- بررسی خصوصیات الگوریتم مورد استفاده و به خصوص ویژگی Importance
- محاسبه مقادیر نسبی (فراوانی نسبی) باندهای تصویر نرمال شده
- تبدیل مقادیر نسبی به feature collection و نمایش آنها بصورت چارت
- مرتبط ساختن داده های تست با تصویر ماهواره ای نرمال شده
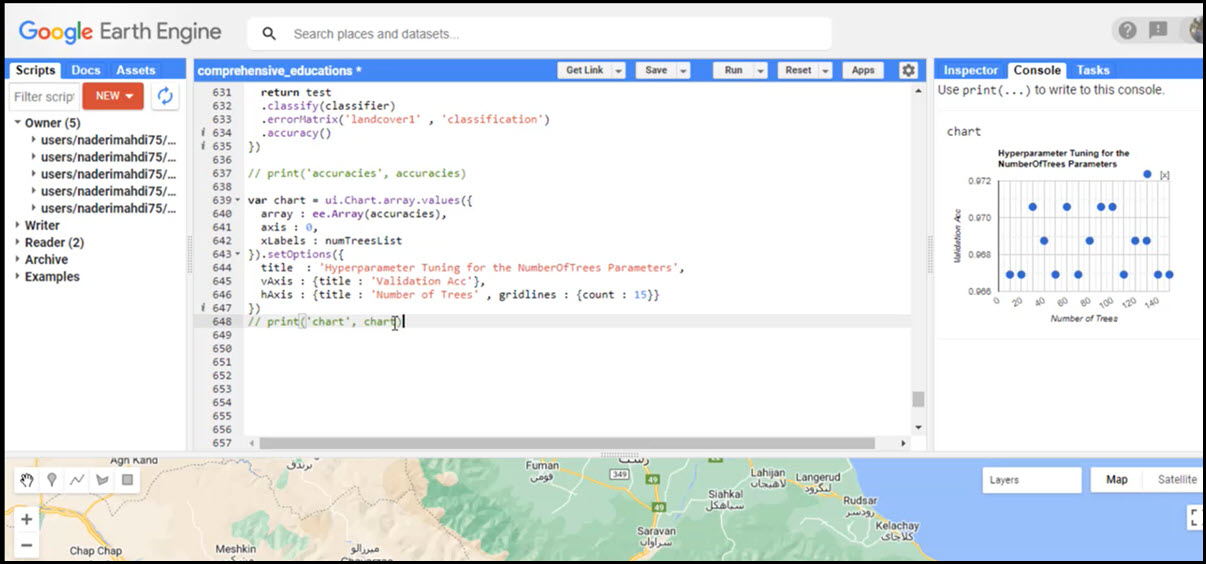
- تنظیم فراپارامتر تعداد درختان (Number of Trees) به صورت جداگانه
- نمایش تعداد درخت مناسب با صحت کلی با استفاده از چارت
- تنظیم فراپارامتر های تعداد درختان و نرخ تقسیم (bagFraction) به صورت همزمان
- اخذ خروجی CSV و مقایسه فراپارامتر های تعداد درختان و نرخ تقسیم مناسب با صحت کلی
معرفی نرم افزار
در این محصول جامع آموزشی به منظور پیشبرد اهداف تعریف شده از سامانه گوگل ارث انجین استفاده شده است. سامانه تحت وب که به طور گسترده به منظور پردازش تصاویر ماهواره ای مورد استفاده قرار می گیرد. گوگل ارث انجين(GEE) يک پلتفرم ابري است که براي ذخيره و پردازش مجموعه داده هاي بزرگ (در مقياس پتابايت) طراحي شده است. همچنین می توانید آموزش گوگل ارث انجین در Girs مشاهده کنید.
این سامانه، امکان مشاهده سريع داده ها با قابليت بزرگنمايي، تغيير مکان در هر نقطه از کره زمين و استفاده از داده هاي سري زماني جهت بررسي تغييرات در طول زمان را فراهم مي کند. در اين سامانه نيازي به جديدترين پردازشگرها يا جديدترين نرم افزار نيست، به اين معني که محققان فقيرنشين در فقيرترين ملت هاي جهان توانايي انجام تجزيه و تحليل هاي پيشرفته را دارند.
قسمت سمت کاربر (front-end) که به راحتي در دسترس و بسيار کاربرپسند است، محيط مناسبي را براي توسعه داده ها و الگوريتم هاي تعاملي فراهم مي کند. ضمن استفاده از منابع ابري گوکل براي انجام کليه پردازش ها، کاربران همچنين مي توانند داده ها و مجموعه هاي خود را اضافه و تصحيح کنند. این سامانه می تواند در جهت پیشبرد اهداف محقق ها در حوزه های مختلف مطالعاتی مانند منابع طبیعی، زمین شناسی، خاکشناسی، منابع آب، کشاورزی، اقلیمی و … کاربرد داشته باشد.
داده ها
در این محصول از داده ها و لایه های مختلف اطلاعاتی استفاده شده است. تصاویر ماهواره ای سنتنیل-2 که از جمله ماهواره های چندطیفی که توسط سازمان فضایی اروپا به فضا فرستاد شده است. این ماهواره دارای 12 باند بوده که در محدوده های مرئی و مادون قرمز تصویربرداری می کند و دارای قدرت تفکیک مکانی 10، 20 و 60 متر برای انواع باند ها می باشد.
قدرت تفکیک زمانی این ماهواره اگر به صورت منفرد مورد استفاده قرار گیرد، 10 روز و اگر بصورت جفت (سری های A , B) مورد استفاده قرار گیرند، به 5 روز تقلیل می یابد. از دیگر لایه های اطلاعاتی مانند مدل رقومی سطح یا Digital Surface Model سنجنده ALOS که به صورت جهانی و با وضوح مکانی 30 متر عرضه می گردد نیز استفاده شده است.
همچنین شاخص های مختلف طیفی در این محصول آموزشی مورد محاسبه قرار گرفته تا در نهایت نتایج مطلوب با بکارگیری منابع مختلف اطلاعاتی حاصل شود.
کاربرد این محصول
همانطور که عنوان شد، این محصول جامع آموزشی متشکل از بخش های مختلفی است که می تواند مد نظر کارشناسان حوزه سنجش از دور و مطالعات کشاورزی قرار گیرد. اهمیت بخش های مختلف این محصول جامع آموزشی به شرح زیر ارائه می گردد :
1.نرمال سازی تصاویر ماهواره ای :
به عنوان یک کاربرد خاص از نرمال سازی تصاویر ماهواره ای می توان به فرآیند طبقه بندی یا Classification اشاره کرد. زمانی که علاوه بر باند های تصاویر ماهواره ای، سایر اطلاعات جانبی مستخرج از شاخص های طیفی یا سایر لایه های اطلاعاتی مانند مدل های رقومی ارتفاعی در فرآیند طبقه بندی دخیل می شوند، نرمال سازی تصویر اهمیت پیدا می کند چرا که تحقیقات و مطالعات مختلف نشان دادند که روش های یادگیری ماشین زمانی بهترین عملکرد خود را دارند که لایه های مختلف اطلاعاتی نرمال شده باشند. نرمال سازی تصویر با روش های مختلفی قابلیت انجام را دارا می باشد که از آن جمله آن روش ها می توان به روش استفاده از مقادیر حداقل و حداکثر و همچنین روش نمره آماری z یا Z-Score اشاره کرد.
نمره z، یک مقدار آماری است که به ما اعلام می دارد، یک عدد خاص چه میزان انحراف معیار از میانگین کل مجموعه داده های ما فاصله دارد.
2.معیار های کمی تفکیک پذیری کلاس های کاربری :
در مقابل روش های کیفی بررسی تفکیک پذیری کلاس های کاربری مانند نمودار بازتاب طیفی (Spectral Signature)، روش های کمی مطرح هستند. به عنوان یک کاربرد خاص از بررسی تفکیک پذیری کلاس های کاربری می توان به فرآیند طبقه بندی اشاره کرد چرا که هر چقدر تفکیک پذیری کلاس های کاربری بیشتر باشد، الگوریتم طبقه بندی کننده عملکرد بهتری خواهد داشت.
ذکر این نکته حائز اهمیت است که تفکیک پذیری بین کلاس های کاربری قرار نیست که در همه باند های یک تصویر رخ دهد چرا که وجود همپوشانی یا overlay بین کلاس های مختلف منجر به کاهش تفکیک پذیری آنها خواهد شد. در بررسی تفکیک پذیری بین کلاس های کاربری به هر کلاس کاربری به دید یک تابع توزیع آماری نگاه می کنیم.
فراوانی داده ها در یک مجموعه یا کلاس کاربری توسط تابع توزیع آماری مشخص می شود. در نتیجه برای هر کلاس کاربری و برای هر باند، تابع توزیع متفاوتی داریم.
برای پیدا کردن فاصله دو تابع، فاصله بین میانگین دو کلاس برای ما اهمیت دارد اما صرفا معیار میانگین کافی نیست و دلیل آن پراکنش داده ها می باشد. در واقع باید به دنبال معیاری باشیم که پراکنش داده ها را نشان دهد. یک شاخص کمی موفق برای تعیین تفکیک پذیری دو کلاس در یک باند باید علاوه بر میانگین تابع توزیع کلاسها، میزان انحراف معیار را نیز در نظر بگیرد. در سنجش از دور برای تعیین پراکنش داده ها از کوواریانس استفاده می شود.
از جمله روش های کمی تفکیک پذیری کلاس های کاربری میتوان به فاصله ماهالانوبیس، فاصله باتاچاریا و فاصله جفریس-ماتوسیتا اشاره کرد.
3.شناسایی داده های زمینی (GCPs) به اشتباه طبقه بندی شده :
بالطبع از جمله مباحث کاربردی است که می تواند در بحث طبقه بندی و مطالعات کاربری اراضی مد نظر قرار گیرد. شناسایی داده های زمینی مرتبط با یک کلاس کاربری و ثانیا مرتبط با تمام کلاس های کاربری که به اشتباه طبقه بندی شدند، از جمله مواردی است که نه تنها می تواند در بارزسازی آن نقاط موثر باشد بلکه می تواند عملکرد الگوریتم طبقه بندی کننده را نیز مورد بررسی قرار دهد.
4.تنظیم فراپارمتر های الگوریتم جنگل تصادفی :
هایپرپارامتر یک پارامتر یادگیری ماشین است که مقدار آن قبل از آموزش الگوریتم یادگیری انتخاب می شود. فراپارامترها نباید با پارامترها اشتباه گرفته شوند. در یادگیری ماشین (Machine Learning)، از پارامتر برای شناسایی متغیرهایی استفاده می شود که مقادیر آنها در طول آموزش آموخته می شود. پیشوند hyper برای شناسایی پارامترهای سطح بالاتری که فرآیند یادگیری را کنترل میکنند استفاده میشود.
شما به عنوان یک مهندس یادگیری ماشین یا مهندس هوش مصنوعی که یک مدل را طراحی می کنید، مقادیر فراپارامتری را انتخاب و تنظیم می کنید که الگوریتم یادگیری شما قبل از شروع آموزش مدل از آنها استفاده کند. هایپرپارامترها خارج از مدل هستند زیرا مدل نمی تواند مقادیر خود را در طول یادگیری/آموزش تغییر دهد. در پایان فرآیند یادگیری، ما پارامترهای مدل آموزش دیده را به انضمام هایپرپارامترهایی که در طول آموزش مورد استفاده قرار گرفتند و بخشی از این مدل نیستند را خواهیم داشت. مهم است که قبل از شروع آموزش، فراپارامترهای مناسب را انتخاب کنید، زیرا این نوع متغیر تأثیر مستقیمی بر عملکرد مدل یادگیری ماشین ایجاد شده دارد.
فرآیند انتخاب فراپارامترهایی که باید استفاده شود، تنظیم فراپارامتر نامیده میشود.
نمونههایی از فراپارامترها در یادگیری ماشین عبارتند از:
- تعداد و اندازه لایه های مخفی در شبکه های عصبی
- تعداد درختان در الگوریتم جنگل تصادفی
- نرخ تقسیم در الگوریتم جنگل تصادفی : درصد داده ی آموزشی در هر تکرار را که به وسیله ی کاربر تعیین میشود، مشخص میکند.
مخاطبین
مخاطب این محصول، افراد متخصص در حوزه سنجش از دور، مطالعات کشاورزی، مطالعات منابع طبیعی، مطالعات محیطی، مطالعات کاربری اراضی و … هستند. مطالب ارئه شده در این محصول جامع آموزشی علاوه بر کاربردی بودن، از جدید ترین آموزش های حوزه سنجش از دور و مطالعات کاربری اراضی محسوب می شود که افراد مختلف می توانند در جهت پیشبرد اهداف خود از آنها استفاده کرده و نتایج مطلوب را کسب کنند.
در این محصول آموزشی سعی شده است تا مطالب به صورت شیوا و رسا بیان شوند تا برای افرادی که آشنایی حداقلی با تصاویر ماهواره ای، شاخص های طیفی و سامانه گوگل ارث انجین دارند نیز قابل استفاده باشد.
تهیه آموزش
جهت تهیه این اموزش بر روی دکمه زیر 👇 کلیک کنید و پس از پرداخت وجه بلافاصله ویدئوهای آموزشی را دانلود نمایید:
نوشته های مرتبط :







آموزش های رایگان پیشنهادی :


آموزش رایگان گوگل ارث انجین (GEE) و مبانی آن
6,271 بازدید






آموزش مکان یابی به روش بولین در GIS
4,224 بازدید

طراحی شاخص طیفی در 10 دقیقه
775 بازدید
4 دیدگاه. ارسال دیدگاه جدید
سلام و احترام و تشکر از مطالب دوره . نتیجه اعمال feature importance ارزش و score ای هست که هریک از فیچرها در نمونه های اموزشی بدست می اورند . سوال اینه که ایا میشه ازبین فیجرها اوندسته از فیچرهای که ی حدی بالاتر هستند را انتخاب و طبقه بندی را انجام داد . ایا این عمل در میزان دقت طبقه بندی موثر هواهد بود . ترکیب بهینه فیچر ها را چطور بدست بیاریم ؟
با سلام و احترام
سپاس از دیدگاه شما.
تا الان چنین موردی رو حداقل در کارهایی که انجام دادهام، مورد توجه نبوده است اما خب زمانی که شما متغیر relative importance رو برآورد میکنید، بنظر منطقی میاد که میتونید با اعمال یک حدآستانه نسبت به انتخاب نمونههای مطلوب اقدام بکنید (به عنوان مثال : relative importance بزرگتر از یک مقدار مشخص) و در نهایت featureCollection خودتون رو بسازید و وارد فرآیند طبقهبندی بکنید. البته باید در نظر داشته باشید که اگر قرار بر اعمال حدآستانه باشد، چه مقداری را برای relative importance در نظر بگیرید که متاسفانه اطلاعاتی در این خصوص ندارم اما می تونید زمانی که نتایج relative importance را بصورت chart ترسیم می کنید، یک خروجی اکسل بگیرید و مقادیر را بررسی کنید که بتواند در انتخاب حدآستانه به شما کمک کند.
قاعدتا انجام فرآیند طبقه بندی با نمونههای خالص تر و مطلوبتر، در دقت نتایج هم تاثیرگذار خواهد بود اما اینکه چقدر دقت را افزایش خواهد داد، باید تست شود.
با سلام مجدد منظور بنده از(FI) Feature importance ویژگی ها ،داده های چون شیب ارتفاع ، NDVI و باندهای طیفی هست که بعنوان دیتاست آماده می شود که در محل نمونه آموزشی مقدار این مغییر دیتاست یا ویژگی محاسبه می شود. که خوب حروجی اعمال این FI هم گرافیکی و هم جدولی CSV هست که SCORE و اهمیت هر یک از ویژگی ها و یا لایه های در مجموعه دیتاست نشون میده . حال سئوال اینه که از بین این SCORE ها اون وژگی های بهینه ای را برای امر طبقه بندی انتخاب کنیم که SCORE بالای دارند تا اولا در تعدد ويژگی ها و هندسه محدوده تعادلی ایجاد شود که اولا دقت طبقه بندی بالا بره و از طرفی بحث COMPUTIONAL ERROR رخ ندهد . تشکر مجدد
بسیار عالی
بنده سوال شما رو پس اشتباه متوجه شدم و رفتم سمت تنظیم ابر پارامترها چون اونجا بحث feature importance رو عنوان کردیم.
بله درست میفرمایید اما خب بنظر باید توجه کنیم که حالا بر اساس ویژگی های با score بالا اومدیم و طبقه بندی رو انجام دادیم. به گونه ای با این کار داریم تعداد ویژگی ها رو هم کاهش میدیم هر چند ویژگی هایی که موندن، score بالایی دارند اما از طرفی ما با کاهش ویژگی روبه رو هستیم. در این حالت باید دید که الگوریتم طبقه بندی کننده میتونه با همون ویژگی های با امتیاز بالا، دقت خوبی رو ارائه بده یا نه.
در خصوص حجم محاسبات، فرمایش شما متین است
موفق باشید